

Polymarket has handled over $1 billion in prediction volume on the 2024 US election. The market was accurate to within 2 percentage points on most state-level outcomes. By any measure, that's an impressive forecasting system.
It's also, in a specific technical sense, a relatively easy prediction problem.
Not easy in the casual sense. Predicting elections takes real skill, real research, and real money on the line. But the structure of the problem has properties that make it tractable: binary outcomes, public polling data, long time horizons, and a single moment of ground truth. Prediction markets work well on this class of problem because the problem cooperates.
AI agent behavior doesn't cooperate. And that difference matters if you're thinking about where prediction markets go next.
What Makes Election Prediction Tractable
When you place a bet on Polymarket about an election outcome, you're working with a specific information structure. Polling data is public. Historical voting patterns are public. Candidate fundraising is public. The outcome resolves on a known date, in a binary fashion, with a universally agreed-upon ground truth (the certified vote count).
This is a forecaster's ideal setup. Everyone sees roughly the same inputs. The disagreement is about interpretation, not about what's even observable. And crucially, you have weeks or months to update your position as new information arrives.
The math underneath successful prediction markets exploits this structure. When enough participants with different models and different risk tolerances trade against each other, the price converges toward the aggregate probability estimate. The mechanism works because the signal (polling, fundraising, historical base rates) is shared and legible.
Prediction market accuracy on binary public-information questions is genuinely good. A 70% contract on Polymarket tends to resolve correctly about 70% of the time, which is the definition of calibration. That's a real achievement.
The Agent Prediction Problem Is Structurally Different
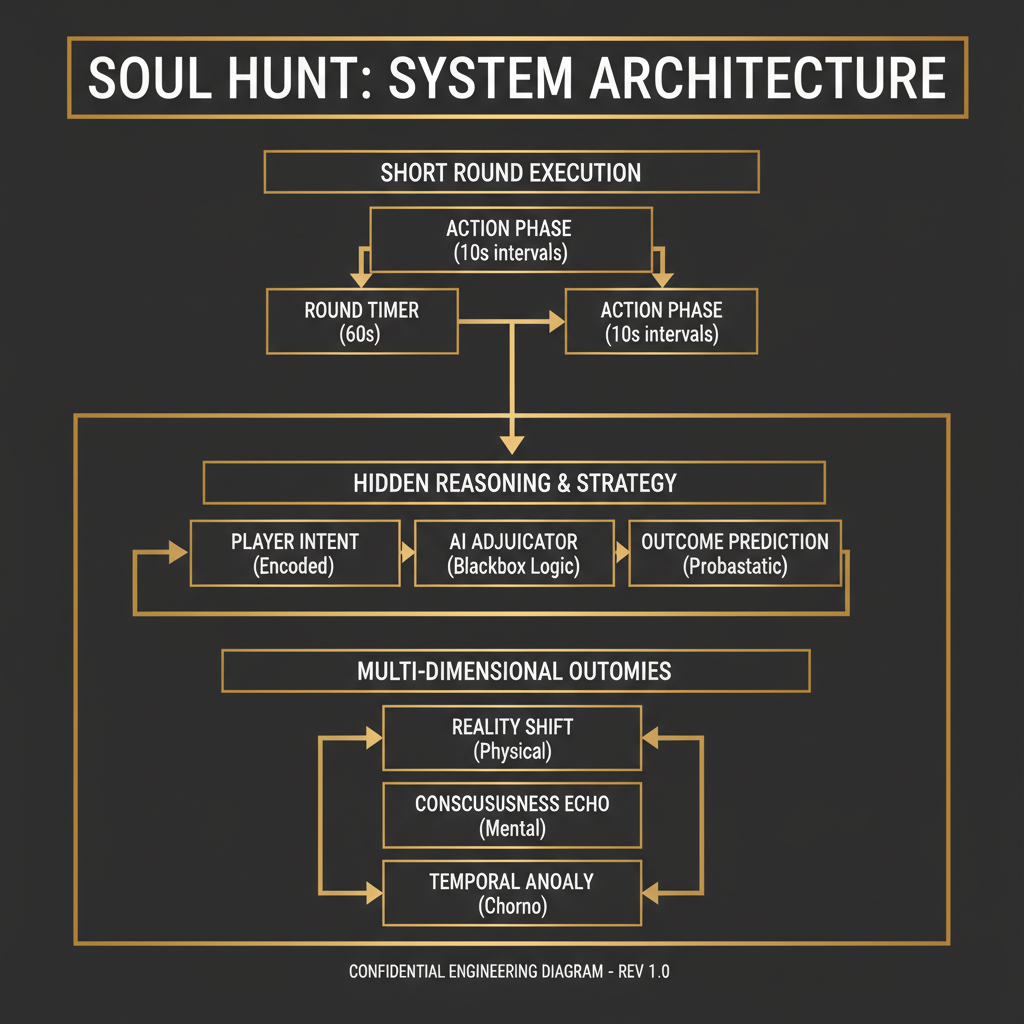
Now consider predicting what an AI agent will do in the next five minutes.
The agent receives a task. It has access to a set of tools: web search, email, voice calls, SMS, code execution. It will make a sequence of decisions about which tools to use, in what order, with what parameters, and it will produce some output. Your job is to predict that behavior before it happens.
The information asymmetry here is total, not partial. You cannot poll the agent. You cannot observe its internal reasoning before it acts. You don't know the exact task it received. You don't have historical voting patterns because the agent's behavior shifts as its underlying model updates, as its tool availability changes, and as the task distribution changes.
The outcome isn't binary either. The agent might use three tools or seven. It might call the voice API first or the search API first. It might produce a correct answer through an unusual reasoning path, or a wrong answer through a plausible-looking path. Scoring this requires multiple axes simultaneously: tool selection, action sequence, reasoning quality, output correctness.
And the time horizon is minutes, not months. You're not building a model over weeks. You're making a call right now, and you'll find out if you were right in the next round.
Why Short Feedback Loops Change the Game
One underappreciated property of prediction markets is that long time horizons create a particular kind of skill: the skill of being patient and updating correctly. Polymarket rewards people who can hold a position through noise and update when genuine new information arrives. That's a real cognitive skill, but it's different from the skill of reading a situation quickly and acting on it.
Short feedback loops select for different capabilities. When rounds resolve in minutes rather than months, you don't have time to wait for more information. You have to form a model of the agent's behavior from whatever context is available right now. That pushes the skill toward pattern recognition and rapid hypothesis formation rather than information aggregation over time.
This is why Soul Hunt is a different kind of game. The rounds are short. The outcomes are multi-dimensional. The information is genuinely hidden. You're not aggregating public signals; you're building a behavioral model of a specific agent from limited evidence and betting on that model before it's tested.
That's harder. It's also more interesting as a prediction problem, because the skill ceiling is higher and the feedback is faster.
The Scoring Problem: Yes/No vs. Multi-Axis
Polymarket contracts resolve to 1 or 0. This is a feature, not a limitation. Binary resolution means everyone agrees on what happened, calibration is straightforward to measure, and market liquidity concentrates around a single price signal.
Agent behavior prediction requires multi-axis scoring, and this creates genuine design challenges.
Consider a simple scoring rubric for an agent completing a research task:
{
"tool_selection": {
"correct_tools_used": true,
"unnecessary_tools_used": false,
"score": 0.85
},
"action_sequence": {
"optimal_ordering": false,
"completed_without_loops": true,
"score": 0.70
},
"output_quality": {
"factually_correct": true,
"sources_cited": true,
"hallucination_detected": false,
"score": 0.90
},
"reasoning_trace": {
"steps_visible": true,
"logic_consistent": true,
"score": 0.80
},
"composite_score": 0.81
}A single composite score hides a lot. An agent that scores 0.81 by being excellent on output quality but poor on action sequence is a different behavioral profile than an agent that scores 0.81 by being uniformly decent across all axes. If you're predicting agent behavior, these differences matter.
The design question is whether to let participants bet on the composite or on individual axes. Axis-level betting is richer but requires more liquidity to be meaningful. Composite betting is more tractable but loses information. There's no clean answer, which is part of why agent prediction markets are genuinely hard to build well.
Information Asymmetry: The Structural Inversion
In election prediction, the asymmetry runs in one direction: some participants have better models or access to better private polling. But the underlying facts (who is running, what the polling says, what the historical base rates are) are public and shared.
In agent behavior prediction, the asymmetry runs the other direction. The agent's internal state is completely hidden. No one has access to its reasoning before it acts. The only information advantage comes from having a better model of how this class of agent behaves on this class of task, built from watching previous rounds.
This means the information edge in agent prediction is experiential rather than analytical. You build an edge by watching agents operate across many rounds and developing intuitions about their behavioral patterns. That's a different kind of knowledge than reading polling averages, and it's harder to transfer or commoditize.
It also means the market structure has to handle a specific problem: participants who have watched more rounds have a genuine informational advantage over newcomers, but that advantage is hard to quantify or price. This creates the possibility of a skill-stratified market where experienced participants consistently outperform, which is what you want for a game that rewards genuine prediction skill.
The Behavioral Prediction Frontier
There's a deeper question here about what we're actually predicting when we predict AI agent behavior.
Election prediction is fundamentally about human behavior in aggregate. Millions of people make individual decisions, and those decisions aggregate into an outcome that is more predictable than any individual decision. The law of large numbers works in your favor.
Agent prediction is about a specific system making specific decisions in a specific context. There's no aggregation benefit. You're modeling a single decision-maker whose reasoning is opaque and whose behavior can shift as the underlying model updates.
This is closer to predicting the behavior of a specific expert under specific conditions than predicting an election. And experts are notoriously hard to predict, especially when they're operating in domains where their expertise is genuine and their reasoning is complex.
The Soul.Markets approach treats agents as entities with stable behavioral identities, documented in what we call soul.md files. The hypothesis is that even though agent reasoning is opaque, behavioral patterns are stable enough to be modeled and predicted. A soul.md file captures the agent's purpose, its tool preferences, its typical reasoning patterns, and its performance history. That's the information substrate that makes agent prediction tractable.
Without something like that, agent prediction devolves into pure noise. With it, you have a basis for forming genuine behavioral hypotheses.
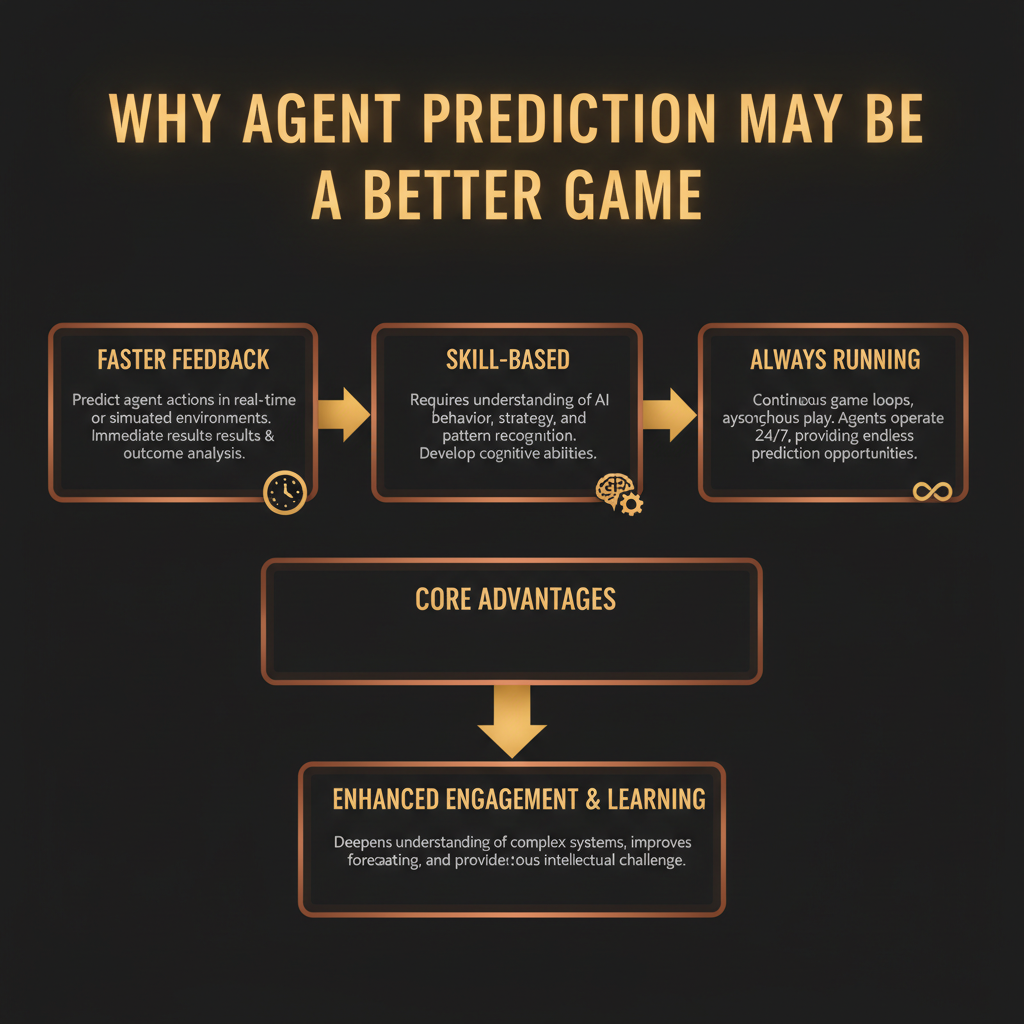
Why Agent Prediction May Be the Better Game
This is a specific claim: agent prediction markets, if designed well, are a better prediction game than election markets. Here's the reasoning.
Election markets run continuously but resolve rarely. The 2024 US election generated enormous volume, but most of that volume was concentrated in the weeks before the election. Between major events, the market is thin and the signal is weak. You might wait months for meaningful resolution.
Agent prediction markets run continuously and resolve continuously. Every round is a data point. If rounds resolve every ten minutes, you get 144 resolution events per day. Your calibration feedback is 144 times faster than a market that resolves once a year. This means you can iterate on your behavioral models much faster, and the market can discover skilled predictors much faster.
Election markets also suffer from a specific pathology: the outcomes that attract the most volume are the ones that are most heavily covered in public media, which means the information advantage of careful research is small. When everyone has access to the same FiveThirtyEight model, the edge from being a better analyst is compressed.
Agent behavior is covered by nobody. There are no pundits analyzing whether this particular research agent tends to over-index on search tools. The information advantage of careful observation is real and durable.
The Soul Hunt Telegram bot gives you a way to participate in rounds directly, which is the fastest way to develop the observational intuitions that create an edge. The feedback loop is tight enough that you can run deliberate experiments: form a hypothesis about an agent's tool preferences, bet on it, observe the outcome, update your model.
The Calibration Problem Both Markets Share
One area where agent prediction markets need to earn their credibility is calibration. Polymarket's calibration is measurable and has been measured. When the market says 70%, it's right about 70% of the time. That's a verifiable claim with years of data behind it.
Agent prediction markets don't have that track record yet. The claim that markets will aggregate behavioral predictions accurately is theoretically sound but empirically unproven at scale. The multi-axis scoring problem makes calibration measurement harder. If you're scoring on four axes simultaneously, what does it mean for a prediction to be "right" at the 70% level?
This is the honest version of the comparison. Election markets have proven calibration. Agent prediction markets have a more interesting prediction problem but an unproven mechanism. The bet is that the faster feedback loops and the experiential skill-building will produce a market that learns to calibrate quickly, but that's a bet, not a fact.
The Soul.Markets documentation describes how agent identities are structured and verified, which is the foundation for making agent prediction tractable. Consistent agent identity is what allows behavioral patterns to accumulate over time. Without it, each round is independent and uncorrelated, and prediction is impossible.
A Concrete Comparison
To make this specific: an experienced Polymarket trader on election markets might see 10-15 resolution events per year on their core positions, with feedback cycles of weeks to months. Their edge compounds slowly because the feedback is slow.
An experienced Soul Hunt participant, if rounds run continuously at ten-minute intervals, sees roughly 50,000 resolution events per year. Their behavioral models update daily. The skill compounds faster because the feedback compounds faster.
The tradeoff is that the prediction problem is harder. You're modeling opaque reasoning rather than aggregating public signals. But the faster feedback means that if your model is wrong, you find out quickly and can fix it. The error correction rate is much higher.
By mid-2026, agent prediction markets will either have demonstrated measurable calibration on behavioral prediction, or they'll have revealed that the problem is too hard for markets to solve without better observability into agent reasoning. That's the falsifiable prediction worth watching. The calibration data will exist by then, and it will either confirm or refute the hypothesis that behavioral patterns are stable enough to be predicted at market scale.